背景介绍
Inception-V3:由谷歌公司2015年提出,初始版本是GoogleNet,是2014年ILSVRC竞赛的第一名,是一个较为复杂的图像特征提取模型。
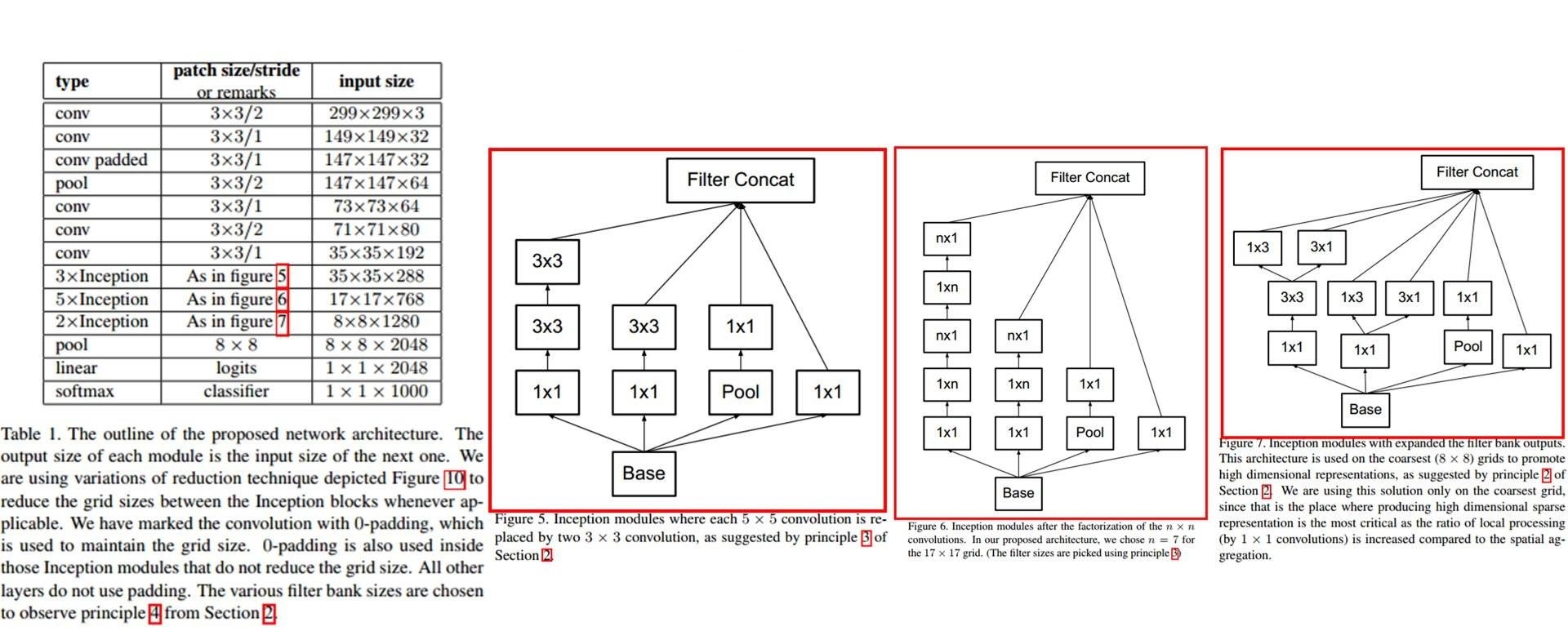
Inception-V3特点
采用不同大小的卷积核,意味着不同大小的感受野,得到不同尺度的特征,最后将不同尺度的特征进行拼接融合
提出卷积分解思想,将一个5x5的卷积,分解为两个3x3的卷积,而且将3x3的卷积分解成一个1x3的卷积和一个3*1的卷积
Spatial Separable Convolution
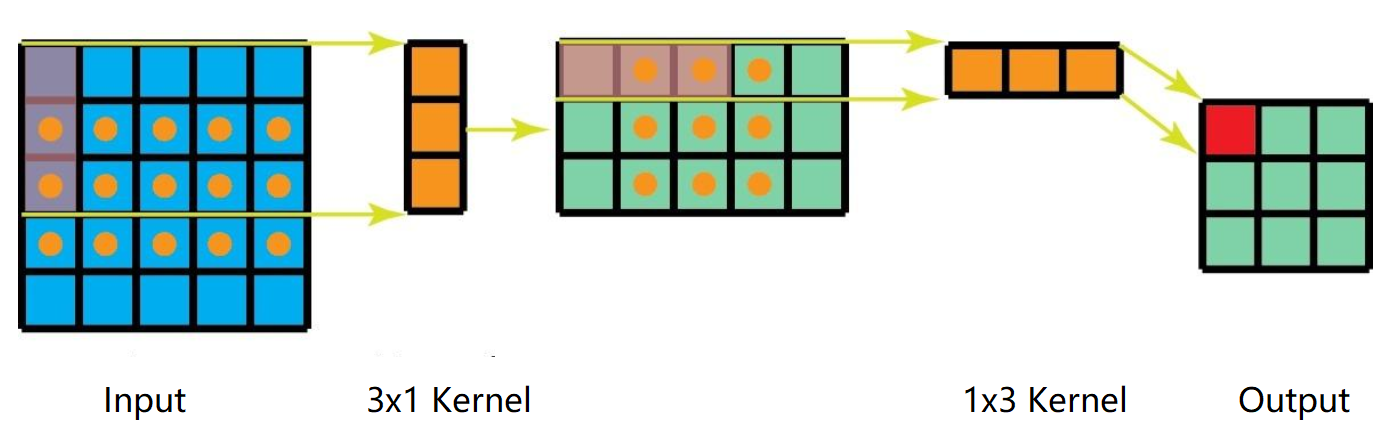
Spatial Separable Convolution(空间可分离卷积):将3x3的卷积分解为3x1的卷积核1x3的卷积,将7x7的卷积分解为7x1的卷积核1x7的卷积.。
主要作用是大大降低网络的参数量。如果一个64x64x256的特征图,经过7x7的卷积核后变为64x64x256的图像,经过普通卷积的参数量为256x(256x7x7+1)=3211520,而空间可分离卷积参数量为2x256x(256x7x1+1)=918016,参数量缩小了约3.5倍。
Inception-V3图像分析
Inception-V3网络结构较大,建议小伙伴们保存到本地放大观看。
TensorFlow2.0实现
1 | from functools import reduce |

Inception-V3小结
Inception-V3是一种复杂的深度学习网络,参数量为22M,由于其结构过于复杂,很少被其他网络所使用,但是其不同感受野和卷积分解的思想给其他网络提供了思路。